Documentation Index
Fetch the complete documentation index at: https://arizeai-433a7140-mikeldking-12899-providers-and-secrets.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Follow with Complete Python Notebook
Follow with Complete TypeScript Tutorial
Why Create a Dataset?
In AI application development, quick iteration can mask regressions or blind spots in quality. Prompt tweaks, model swaps, or architectural changes may seem better in isolation, but without systematic evaluation it’s just guesswork. That’s where datasets come in: they act as structured collections of representative examples that you care about and want to systematically test your application against. A dataset is your definition of the test cases that matter as your system evolves. Each example can capture the input that your application will receive, an expected output, and any metadata such as tags, error types, or model parameters. Datasets provide a reliable foundation for evaluating, tracking, and improving your AI workflows.What Should Your Dataset Contain?
The ideal dataset reflects the core behaviors you want your application to get right. Consider including:- Normal-case examples that represent typical user interactions.
- Edge cases where your application historically struggled.
- Flagged or failed runs pulled from logs, user feedback, or tracing. These illustrate concrete failure modes you want to improve.
- Golden datasets: Curated examples with human-verified or “ideal” outputs that serve as a reliable benchmark.
- Regression datasets: Cases that previously failed or revealed a weakness you want to prevent from re-occurring.
- Real user logs: Production or staging logs captured via Phoenix traces
Define an Agent
To run experiments, you’ll need an application or agent to evaluate. In the reference notebook, you’ll find a customer support agent we’ve created using the Agno framework. Phoenix integrates with many frameworks and LLM providers for easy tracing and evaluation. See the full list below:View All Integrations
Create a Golden Dataset
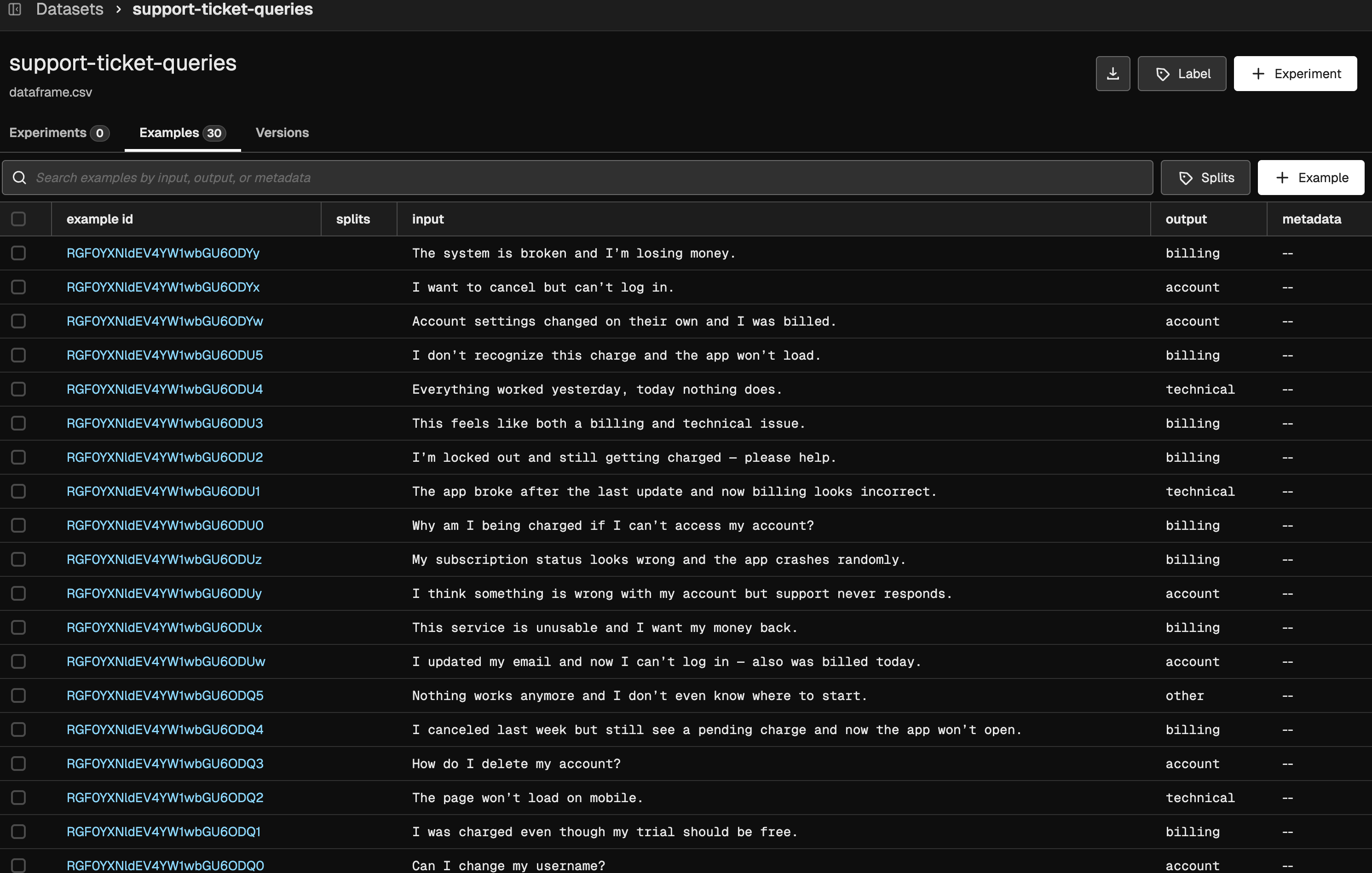
In this tutorial, we’ll create a golden dataset—a dataset that includes reference outputs (also called ground truth) for each example. A golden dataset serves as a benchmark for performance in your experiments, providing a reliable standard against which you can measure and compare your agent’s outputs across iterations. To run experiments in Phoenix, you need a dataset. A dataset provides the structured examples that your experiments use to run and evaluate your agent. Without a dataset, you can’t systematically measure performance, compare different agent versions, or track improvements over time. In our example, each dataset entry contains:- Query: The user input that will be sent to the agent
- Expected Category (Reference Output): The category the agent should classify the query into
- Input keys: Identify the column(s) that contain the model input (ex:
["query"]) - Output keys: Identify the column(s) that contain the reference or ground-truth output (ex:
["expected_category"]) - Metadata keys: Identify column(s) that contain any metadata associated with each record
expected_category field. When uploading, we map query to the input and expected_category to the output.
Upload Dataset